Database Design Patterns for SaaS Applications
When building a multi-tenant SaaS application in Laravel, one of your earliest and most consequential architectural decisions is how you'll structure your database to handle multiple customers. This isn't merely a technical implementation detail. It fundamentally affects your application's scalability, security, data isolation, and operational complexity for years to come.
I've worked with all three major multi-tenancy patterns across different projects, and each brings distinct trade-offs that matter in production. Let me walk through what I've learned about when each pattern makes sense and what to watch for during implementation.
The Three Core Patterns
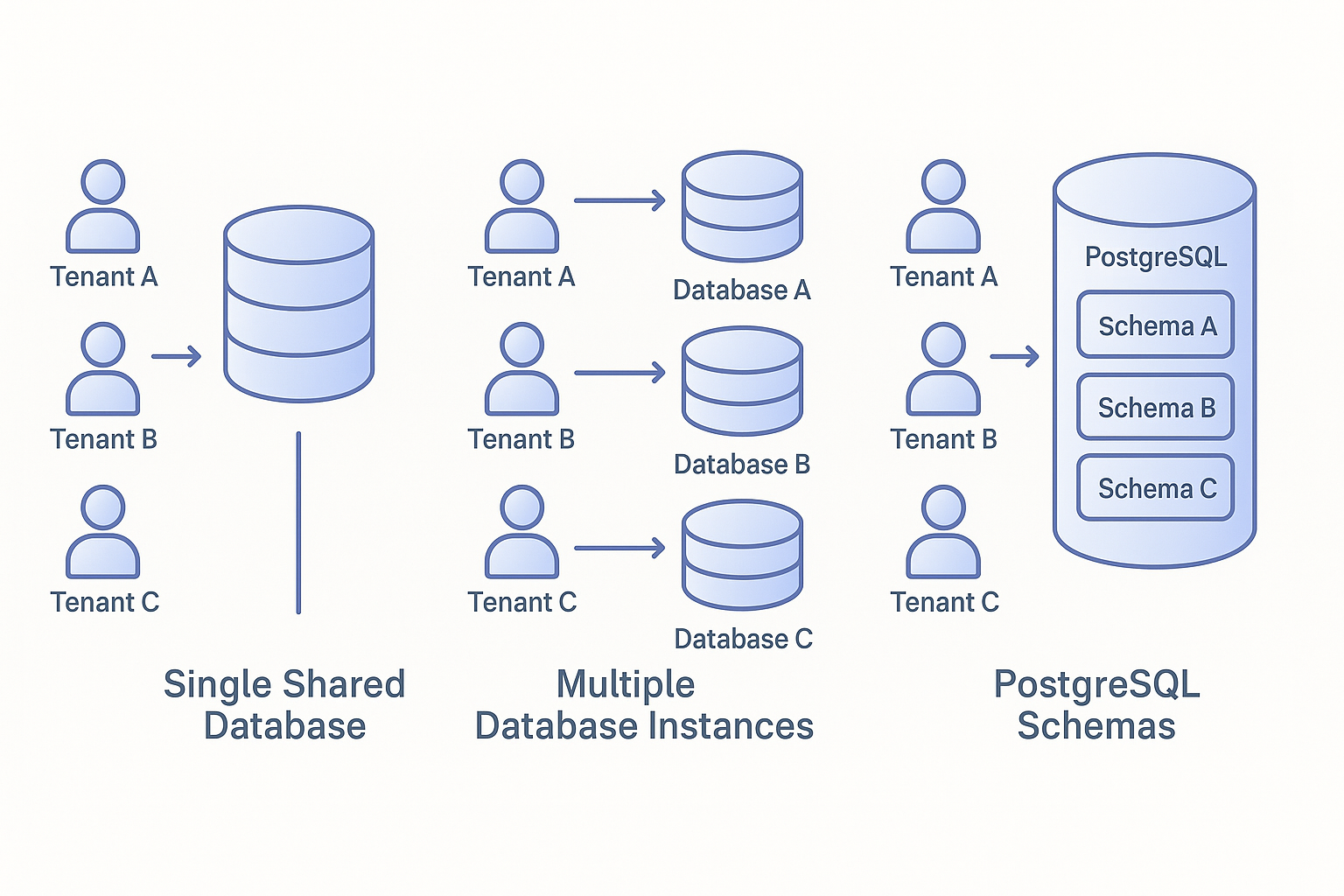
There are three established approaches to multi-tenant database architecture: shared database with tenant identification, database-per-tenant, and a hybrid approach using separate schemas. Each solves the multi-tenancy problem differently, and your choice depends heavily on your specific requirements around data isolation, scale, and operational overhead.
Shared Database with Tenant Identification
This is the most common pattern, particularly for early-stage SaaS products. All tenants share the same database, with a tenant identifier column (typically tenant_id or organisation_id) on every table. Laravel makes this pattern straightforward through global scopes.
The advantages are compelling for many use cases:
This approach maximises database efficiency. You're running a single database instance, which simplifies connection pooling, caching strategies, and backup procedures. Cross-tenant analytics and reporting become trivial since all data lives in one place. Database migrations are straightforward-you run them once, and every tenant receives the update simultaneously.
From a cost perspective, this pattern scales efficiently. You can serve hundreds or thousands of tenants from a single database instance, and scaling vertically (adding more resources to your database server) is usually sufficient until you reach substantial scale.
However, the challenges are significant:
Data isolation relies entirely on application-level logic. A bug in your global scope implementation or a missed WHERE clause can expose data across tenants-a catastrophic failure mode in any SaaS application. I've seen this happen, and the remediation process is extraordinarily painful.
Performance can become problematic as you scale. Large tables require careful indexing strategies, and queries must be optimised to prevent slow tenants from affecting others. The tenant_id column must be part of virtually every index, which increases storage requirements and can complicate query planning.
There's also a noisy neighbour problem. A single tenant performing heavy operations can impact performance for all others sharing that database. You can mitigate this with query timeouts and rate limiting, but you're fundamentally sharing resources.
Database-per-Tenant
At the opposite end of the spectrum, you can provision a separate database for each tenant. This provides maximum isolation and flexibility, and it's the pattern I'd recommend for applications with strict compliance requirements or enterprise customers who demand data separation.
The benefits are substantial:
Data isolation is enforced at the infrastructure level. There's simply no way for a query against Tenant A's database to accidentally return Tenant B's data. This makes security audits more straightforward and provides clear boundaries for compliance frameworks like SOC 2 or ISO 27001.
Performance isolation is complete. Each tenant gets dedicated resources, so one customer's heavy workload doesn't affect others. This is particularly valuable if you serve enterprise clients with unpredictable usage patterns.
You gain flexibility for custom requirements. Enterprise clients often demand specific retention policies, backup schedules, or even geographic data residency. With separate databases, you can accommodate these requests without complexity bleeding into your core application.
But the operational overhead is considerable:
Database migrations become complex. You need orchestration to run migrations across potentially thousands of databases, with proper error handling and rollback strategies. This isn't insurmountable, but it requires robust tooling.
Connection management demands attention. Each database requires its own connection, and connection pooling becomes more complex. You'll likely need a connection broker or careful management of Laravel's database connection system to avoid resource exhaustion.
The cost structure changes fundamentally. You're paying for database resources per tenant rather than amortising costs across your customer base. At scale, this can become expensive, though you can offset costs through pricing strategies.
Backup and monitoring complexity increases linearly with tenant count. You need systems to ensure every database is backed up appropriately and monitored for issues. Forgetting a single tenant's database in your backup rotation is a career-limiting event.
Schema-per-Tenant (PostgreSQL)
PostgreSQL's schema feature provides a middle ground. All tenants share a database instance, but each gets a separate schema-essentially a namespace for tables. This gives you some isolation benefits whilst keeping operational complexity manageable.
This approach offers interesting compromises:
Data isolation is better than the shared database pattern. Schemas provide logical separation, so a query against the wrong schema will fail rather than return incorrect data. This reduces the risk of cross-tenant data leakage from application bugs.
Resource sharing is more efficient than separate databases. You maintain a single connection pool and backup strategy, whilst still providing reasonable isolation between tenants.
PostgreSQL's row-level security can augment this pattern for additional protection, though implementing it adds complexity.
The limitations are worth noting:
This pattern locks you into PostgreSQL. If you might need to support MySQL or other databases, this approach won't work.
Performance isolation is limited. Tenants still share the underlying database resources, so the noisy neighbour problem persists, though it's somewhat mitigated by schema-level resource controls in modern PostgreSQL versions.
Schema management becomes part of tenant provisioning. Creating a new tenant requires creating a schema and running migrations specifically for that schema, which adds operational steps to your onboarding process.
Implementation Considerations in Laravel
Laravel's architecture adapts well to all three patterns, though each requires different implementation strategies.
Global Scopes for Shared Databases
For the shared database pattern, global scopes are essential. They automatically add tenant filtering to all queries, reducing the likelihood of data leakage.
However, global scopes aren't magic. They only apply to Eloquent queries, so raw queries and direct database access bypass them entirely. You must be disciplined about never writing raw queries without explicit tenant filtering.
Testing becomes critical. Your test suite should include cross-tenant access attempts to verify your global scopes work correctly. I recommend writing specific security tests that attempt to access data across tenant boundaries and verify they fail appropriately.
Dynamic Database Connections
For database-per-tenant or schema-per-tenant patterns, you'll need to manage database connections dynamically based on the authenticated tenant.
Laravel's configuration system supports runtime database connection modification, but you need to ensure connections are established early in the request lifecycle-typically in middleware-and that connection pooling doesn't cause unexpected connection reuse across tenants.
The Tenancy for Laravel package handles much of this complexity, and unless you have specific requirements, I'd recommend starting there rather than building from scratch.
Migration Strategies
Schema migrations require careful thought regardless of pattern.
For shared databases, you run migrations once, but you must ensure changes are backwards compatible if you're running a continuous deployment pipeline. Adding nullable columns or new tables is safe; altering existing columns or dropping tables requires careful coordination.
For separate databases or schemas, you need orchestration. Running migrations across hundreds of databases sequentially can take hours, which may be unacceptable for your deployment process. Parallel execution introduces complexity around error handling and rollback procedures.
I've found it valuable to maintain a tenant provisioning checklist that includes migration verification. When onboarding a new tenant, explicitly verify their database schema matches your expected version.
Choosing the Right Pattern
Your decision should be driven by your specific requirements, but here are the factors I consider:
Choose shared database with tenant identification if:
You're building an early-stage SaaS with limited resources and need to move quickly. The operational simplicity lets you focus on product development rather than infrastructure management.
Your tenants are relatively similar in size and usage patterns. This minimises the noisy neighbour problem and makes resource planning predictable.
You don't have strict compliance requirements for physical data separation. Many compliance frameworks are satisfied with logical separation, but some enterprise customers or regulations require more.
Choose database-per-tenant if:
You're targeting enterprise customers who demand data isolation for compliance or contractual reasons. The added complexity is justified by the ability to close deals.
Your tenants have significantly different usage patterns or data volumes. Physical separation makes performance predictable and simplifies capacity planning.
You need flexibility for custom requirements per tenant. Geographic data residency, specific backup schedules, or retention policies all become straightforward with separate databases.
You have the operational maturity to handle the infrastructure complexity. This pattern requires robust automation, monitoring, and orchestration.
Choose schema-per-tenant if:
You're committed to PostgreSQL and value its feature set. If you're not already using PostgreSQL, this probably isn't sufficient reason alone.
You want better isolation than shared databases but can't justify the operational overhead of separate database instances. This pattern genuinely sits in a useful middle ground.
Your tenants are numerous enough that separate databases become unwieldy, but you need logical separation for security or compliance reasons.
My Recommendation for Most Projects
For the majority of Laravel SaaS applications, I recommend starting with the shared database pattern and architecting for future migration to separate databases if needed.
The reality is that most SaaS businesses fail or pivot before reaching the scale where database architecture becomes a limiting factor. Premature optimisation for enterprise requirements you might never have is a waste of resources.
Start simple: implement global scopes thoroughly, write comprehensive tests for tenant isolation, and ensure your application architecture doesn't leak tenant awareness throughout your codebase. Keep tenant identification logic contained in specific layers of your application.
Document your tenant isolation strategy clearly. Future developers-possibly including yourself in six months-need to understand which tables require tenant filtering and why.
Monitor query performance closely and set up alerts for queries that might indicate missing tenant filters. A query scanning millions of rows when it should be filtered to thousands is often a sign that tenant filtering is missing.
When you reach the scale where database architecture becomes a bottleneck-typically tens of thousands of tenants or enterprise customers with specific requirements-you'll have the revenue and operational maturity to handle the complexity of migrating to a more sophisticated pattern.
The proof is in the execution. Many successful SaaS companies, including some serving millions of end-users, run on shared database architectures. The pattern's simplicity lets teams focus on building features that generate revenue rather than managing infrastructure complexity.
Choose the pattern that fits your current reality, not your aspirational scale. You can always migrate later, and by then you'll have actual data about your tenants' behaviour to inform the decision properly.